文 | 壹娱观察 HAL
AI时代,地主家也开始没有余粮了。五一假期里豆包的付费方案悄然出现。
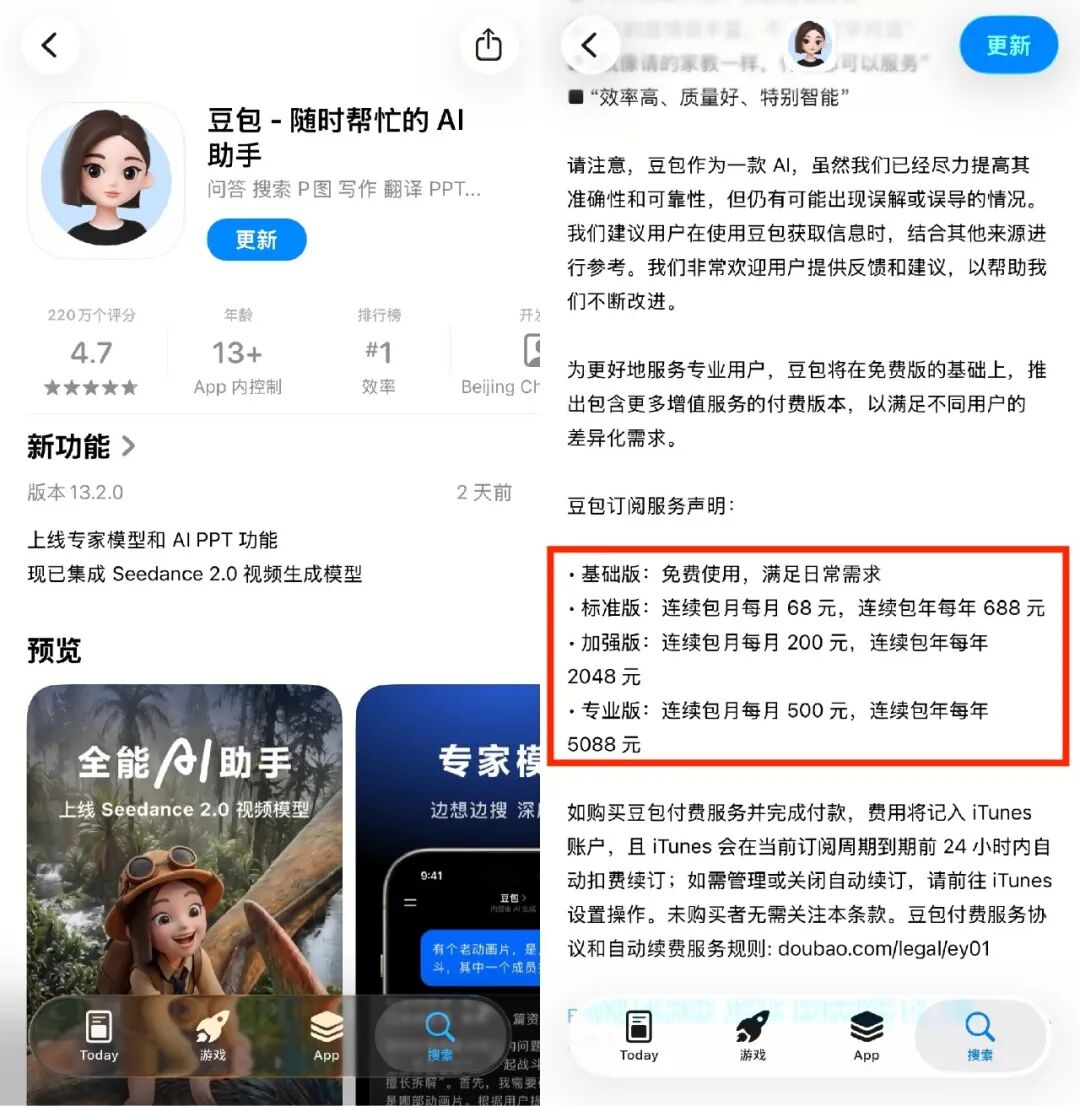
App Store页面更新了介绍,基础版免费,标准版68元/月,加强版200元/月,专业版500元/月。官方随后回应说,免费服务依然提供,付费版属于“增值服务”,方案细节还在测试。
App Store截图
选这个时间点放出消息,大概率不是巧合。假期里媒体节奏放缓,用户注意力分散,任何争议性的动作都更容易被稀释。这当然是一种典型的舆论操控策略——先把消息释出去,等假期结束再看舆论怎么走。
尽管上了热搜,但多数解读角度都是字节成为Kimi之后又一家头部AI产品走向商业化的信号,毕竟海外早已走过这条路,国内迟早要补这一课。
这个判断有一个隐藏前提:海外那条路是走通了的。
事实是,国际AI大厂目前也没有一家在订阅制上跑出正毛利。豆包此刻入局,踩的是海外厂商正在撤离的那条路。
豆包App截图
而比定价模型本身更值得讨论的问题是,这两年国内大厂反复讲述的那个故事——AI会改造一切、AI会成为水电煤一样的基础设施——在算力基建和经济模型的双重约束下,可能从一开始就不成立。
一位长期观察AI行业的分析师Ed Zitron在4月28日发表的AI's Economics Don't Make Sense(AI的经济账根本算不通)全网刷屏,也堪称是最近给了这件事最直白的解释。
月度订阅这种商业模式,前提是单用户成本相对静态、可预测。
健身房可以卖会员,因为它能算清器材损耗、水电人力的大致区间。AI出现之前的Google Workspace也是如此,重度用户最多多占点存储,占不掉订阅毛利。
LLM服务则不是这样。每一个AI订阅用户每个月消耗的算力可以差出几十倍。有人只是偶尔问几句话,有人每天往里塞文档、重构代码库、生成PPT和数据分析报告。
订阅价格固定,成本曲线发散。只要有一小部分重度用户存在,他们就会把这一档的整体毛利吃光。
GitHub Copilot是这个错位的活样本。这款产品最初定价10美元/月,《华尔街日报》披露的数据显示,平均每位用户每月造成的亏损超过20美元,部分重度用户每月给公司造成的成本高达80美元。
微软连续三年补贴了将近200万付费用户的算力差额,撑到2026年终于放弃订阅模式。
应用层公司处境更糟。Cursor把100%订阅收入交给Anthropic换模型访问,自己仍然不盈利。Perplexity在2024年的算力支出占到收入的164%。模型层和应用层都在亏,中间没有夹层去吸收成本。
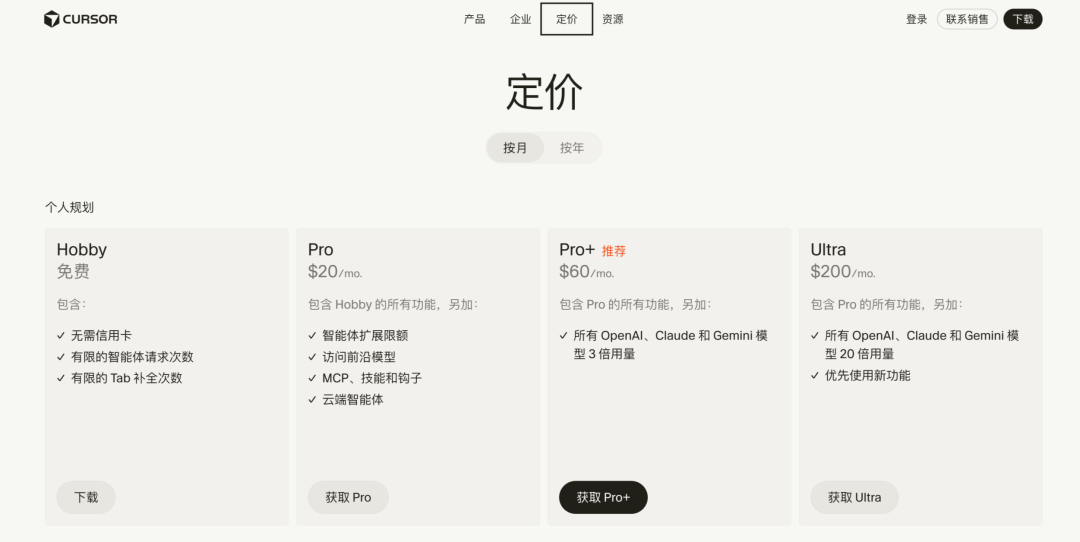
Cursor官网截图
更麻烦的是,行业一度普遍假设token成本会随时间下降,所以早期亏损可以靠规模化消化。但新一代“推理模型”——OpenAI的o系列、Claude的思考模式——单次任务消耗的token是过去的几倍乃至几十倍。
模型变贵的速度,超过了模型变便宜的速度。
Anthropic自己也承认这一点。其增长负责人在解释为什么把Claude Code从Pro档拿掉时说,Claude Pro和Max的扁平订阅“并不是为Claude Code、Cowork这类 Agent 工具而设计的”,原本只是为聊天而设计。
这句话翻译过来是:聊天场景的订阅经济学,其实扛不住Agent场景的算力消耗。
回到豆包身上,它的付费功能定位,根据官方对媒体的回应,主要面向PPT生成、数据分析、影视制作、超长文档解析、专业AI绘画。
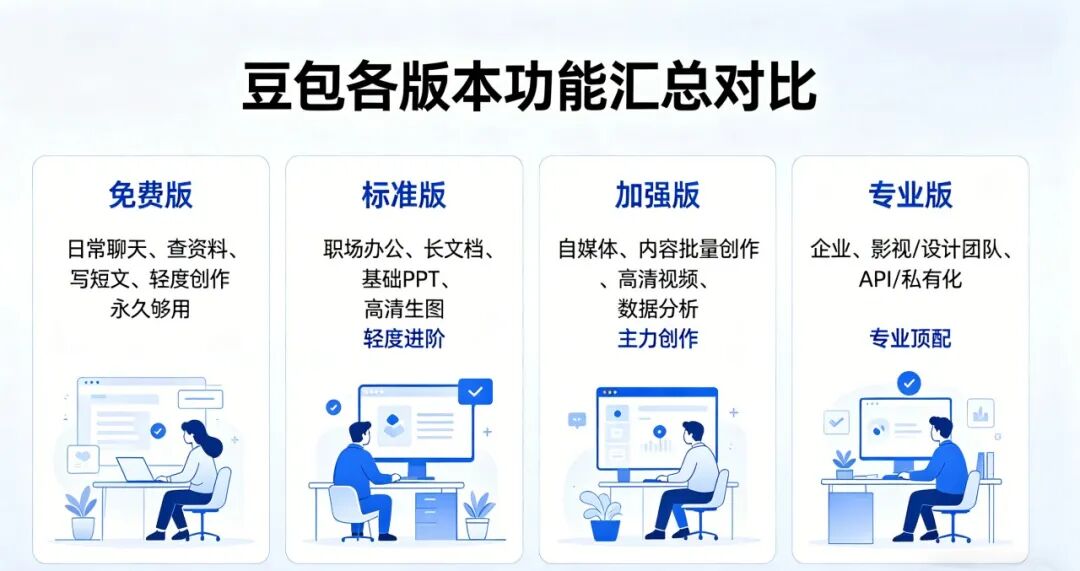
这些恰好都是生产力型重负载,对应 Zitron 说的“用户成本可以差出几十倍”的那个长尾,对应 Anthropic说的扁平订阅扛不住的Agent场景。
豆包等于一开始就站在订阅制最难赚钱的那一边。
68元这一档大概率连基础算力都覆盖不住。200元和500元能否覆盖重度用户的算力消耗,要看豆包对使用频次和token用量的限制做得有多狠。但限制一旦做狠,会员的吸引力就垮掉。毕竟国内的竞争环境甚至要比海外更激烈。除了大厂,还有各位初创公司虎视眈眈。
这是一个先天就没有舒适区的定价结构。
豆包能不能赚钱,或许只是字节AI业务里很小的一个问题。
更值得讨论的,是字节这两年在AI上铺开的整体战线。
底层模型这一层,字节同时在做语言、视频、语音、图像。除了豆包大模型本身,视频生成有Seedance、PixelDance、Seaweed,语音有Seed-ASR 和Seed-TTS,图像有Seedream。光是底层模型就有17款。
应用层铺得更广。chatbot有豆包,图像和视频生成有即梦,智能体开发有扣子,社交陪伴有猫箱,音乐生成有海绵音乐,电商内容有即创,教育有豆包爱学,工具集有小悟空。
编程方向同时押了两条线。Trae是对标Cursor的独立AI IDE,豆包MarsCode则是IDE插件。
海外还有Cici、Coze、Dreamina、Gauth等一整套对应版本。硬件层面甚至已经推到了Ola Friend智能体耳机和地瓜机器人。单是在运营数得出名字的AI应用就超过20款。
这种全产业链铺开的姿态,在用户增长期是合理的。字节作为“应用工厂”,多产品同时跑,跑出谁就重押谁,这套打法在抖音和TikTok时代被反复验证。
但AI不一样。AI的每一条产品线都在持续吃算力,而且越往生产力场景走,吃得越凶。
视频生成尤其如此。它的算力消耗远高于文本生成,每一秒输出都对应着指数级的推理成本。OpenAI为了“集中算力办大事”直接关停了Sora 2,Runway 和Pika的商业化也始终没有跑出健康的单位经济模型。
Seedance的成功的确让人看到了字节大力出奇迹的能力,但即便开始商业化,其也加上了诸多限制,而最核心一条其实还是在算力层面。
但视频生成有多大的商业价值,这条路在战略上是否值得继续加码,可能到了应该重新评估的时候。
算力不足是所有一线AI厂商都要面对的问题。Anthropic、OpenAI和微软的最新动作,本质上都是在做减法——承认有些场景靠现有商业模式喂不饱,主动收缩战线,把算力集中到更可能跑出正向毛利的产品上。
OpenAI关停Sora
这一阶段考验的是战略定力,而不是战略野心。
字节目前还没有出现类似的收缩信号。各条线都在加码,海外海内都在铺,模型和应用都在做。这种姿态的代价,会随着算力成本曲线持续上升而越来越高。
跳出字节看国内大厂,情况其实差不多。
各家大厂其实也都是多线布局,即便底层模型能力有水平差异,但在应用层面几乎没有人愿意放弃“全家桶”战略,其中极少数的例外大概只有一心专注视频生成的快手和基础模型研究的Deepseek。
对大厂而言,每一家都在讲同一个故事——AI会改造一切,AI会成为水电煤一样的基础设施,谁占住了基座,谁就拿到了下一个时代的入场券。
但这个叙事可能从一开始就回避了一个物理层面的问题:当下的算力基建,远远撑不起“AI改造一切”所需要的体量。
OpenAI、Anthropic、微软、亚马逊都在为算力告急。最近最近Anthropic又宣布和马斯克的SpaceX合作,共享后者庞大的数据中心算力资源。
GPU短缺、电力短缺、数据中心建设周期以年计,这些不是一句“加大投入”就能解决的。
国内的情况只会更紧。在芯片受限的前提下,国内大厂的算力天花板比海外更低,但产品线的铺开程度反而更广。这本身就是一个不闭合的等式。
更根本的问题在于,即便算力基建跟得上,AI的规模效应也并不等同于传统互联网时代。
互联网时代的规模效应是边际成本趋零。用户每多一个,服务器成本几乎不增加,所以平台只要烧钱坚持到烧出足够大的规模,最终几乎就一定能够有办法赚钱。
但AI并不符合这套规律,因为AI的边际成本是实打实的算力消耗,用户每多用一次,算力账单就增加一次。
这意味着规模本身不再带来盈利,反而可能放大亏损。
豆包3.45亿月活的体量在传统互联网逻辑里是无敌的资产,在AI经济学里却是一个持续吃算力的成本黑洞。
国内大厂目前还在用互联网时代的逻辑做AI——先抢用户、再做生态、最后变现。但这套逻辑的前提,是规模能转化为利润。如果规模本身就是负担,那这套逻辑就需要被重新审视。
豆包开始收费这件事,从这个角度看,其实是一个迟到的信号——字节也意识到了规模带不来盈利,必须开始想办法收钱。但选择付费订阅制,本身也只是在现成错误的答案里硬选一个。
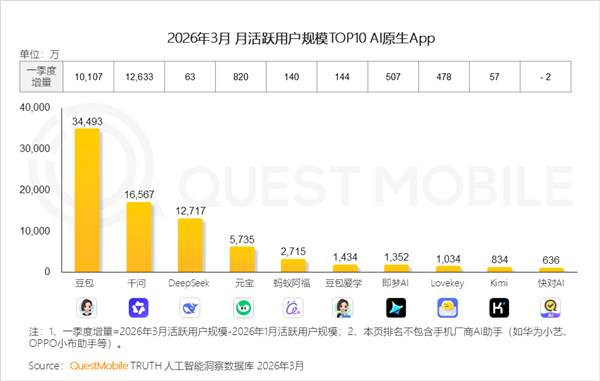
图源:QuestMobile
可以说豆包收费这是个开始,但不是答案。
至于“AI改造一切”、“AI成为基础设施”这些更宏大的叙事或者野心,在算力基建和经济模型双重不闭合的当下,更像是一种行业为了庞大资本支出和支撑股价的自我说服。
这一阶段任何大厂需要的承认现实大概比普通人更多——承认有些事现阶段AI还做不了,承认有些产品现阶段不该做,承认这场竞赛比所有人想象的都要漫长和昂贵。
这个时刻或许终于会开始念起“人”的好来,毕竟“人”还能被欠薪、画饼甚至白嫖,但冰冷的AI可不吃这一套。




















